Seguramente escuchaste hablar de ChatGPT, de hecho, estos últimos meses en Bolivia se han estado promocionando conferencias sobre el uso de la AI o ChatGPT en negocios o en las aulas.

ChatGPT: Chatbots y el poder del lenguaje
Por: Nicaela Leon

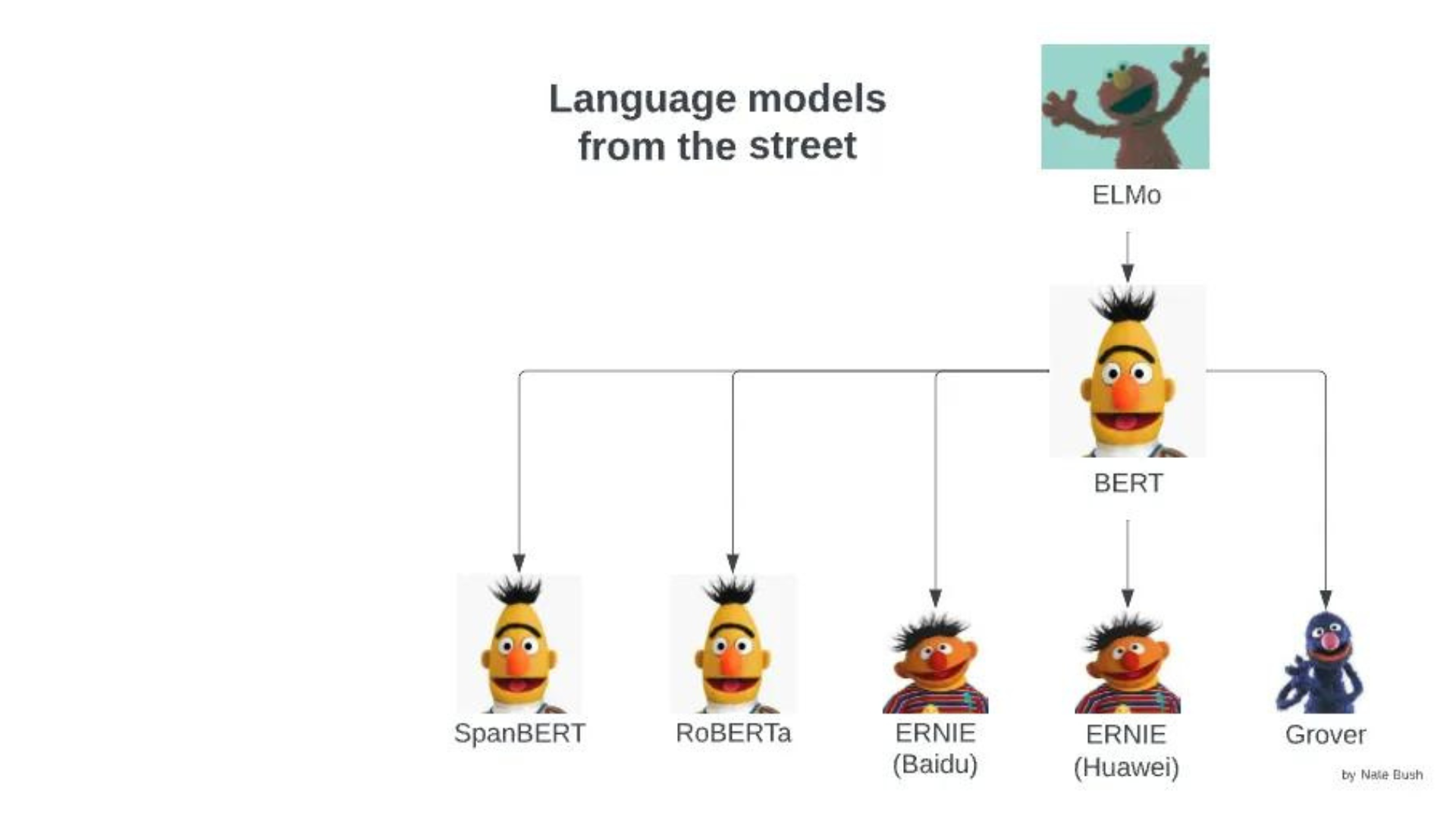
Muchas personas lo consideran algo “nuevo”, sin embargo, no es así. ChatGPT no es el primer chatbot y de seguro que no será el último. Antes de este ya hubo otros modelos de lenguaje antes, como ELMo (2018), BERT (2018) o RoBERTa (2019).

Entonces, ¿Qué es lo que ha hecho que ChatGPT se vuelva tan popular?

En primer lugar, su accesibilidad, a pesar de que existe una versión pagada de ChatGPT Plus, actualmente también tiene una versión gratuita (o al menos por el momento). De hecho, esto no es una coincidencia, pues es sabe que este chatbot también se alimenta de la información compartida por sus usuarios mediante las interacciones con el fin de mejorar. ChatGPT es un modelo de lenguaje, y en la ciencia los modelos son imperfectos, es decir, pueden ser mejorables.
En segundo lugar, su popularidad se debe al lenguaje utilizado. Este chatbot simula una conversación utilizando los datos de entrenamiento que posee, por lo que nos da la impresión de que estamos hablando con una persona. ChatGPT solo combina los datos e información con la que cuenta, no es una máquina pensante que posee competencias comunicativas, como lo define la lingüista Emily Bender, este chatbot es solo un loro estocástico.

La necesidad de humanizar todo…
Hay muchas teorías acerca de porqué los seres humanos tenemos esa tendencia de humanizar los robots. Una de ellas es que no nos gusta estar solos. ¿Estudios como “Can robots tackle late-life loneliness? Scanning of future opportunities and challenges in assisted living facilities”, afirman que los robots disminuyen la soledad emocional y social.
¿Recuerdas la película HER donde Theodore se enamora de una AI?
Pues ahora esto es real gracias a la AI “Replika”, un chatbot que simula conversaciones amistosas o amorosas a sus usuarios y usuarias. Y si pagas la versión pro, esta AI también te ofrece llamadas de voz, sexting y hasta videos de realidad aumentada.

¿Por qué las personas tienen la impresión de charlar con un humano ChatGPT?

La principal tendencia en el desarrollo de las IA es que cada vez resulta más complicado diferenciar si conversamos con una persona o un chatbot. De hecho, el problema de saber diferenciar si hablamos con una máquina o si hablamos con una persona ya fue un tema estudiado a profundidad por Alan Turing, quien en 1950 creó una prueba para evaluar a las IA y que tanto pueden imitar el lenguaje humano.
Se sabe que una de las cosas que nos diferencian a los humanos del resto de los animales es el lenguaje, la capacidad de comunicación. La adquisición del lenguaje en los humanos es un proceso complejo que incluye un proceso de socialización y construcción de significados en la sociedad.
Nosotros los humanos adquirimos el lenguaje desde nuestra infancia debido a que estamos expuestos a la socialización. De acuerdo a un estudio sobre la cantidad de palabras a las cuales está expuesto un niño americano, “American Parenting of Language-Learning Children” de Hart y Risly (1992), en los hogares americanos un infante estaría expuesto a un mínimo de 3 millones de palabras y a un máximo de 11 millones de palabras por año.
Sin embargo, obviamente en el caso de los chatbots no existe tal proceso de adquisición de lenguaje, sino más bien un entrenamiento a partir de un corpus masivo de información extraído de internet, conformado por diferentes formatos, texto, audio y video. Se sabe que ChatGPT ha sido entrenado con información del Buscador de Google, Common Crawl, Wikipedia, Reddit, conversaciones en línea, etc.
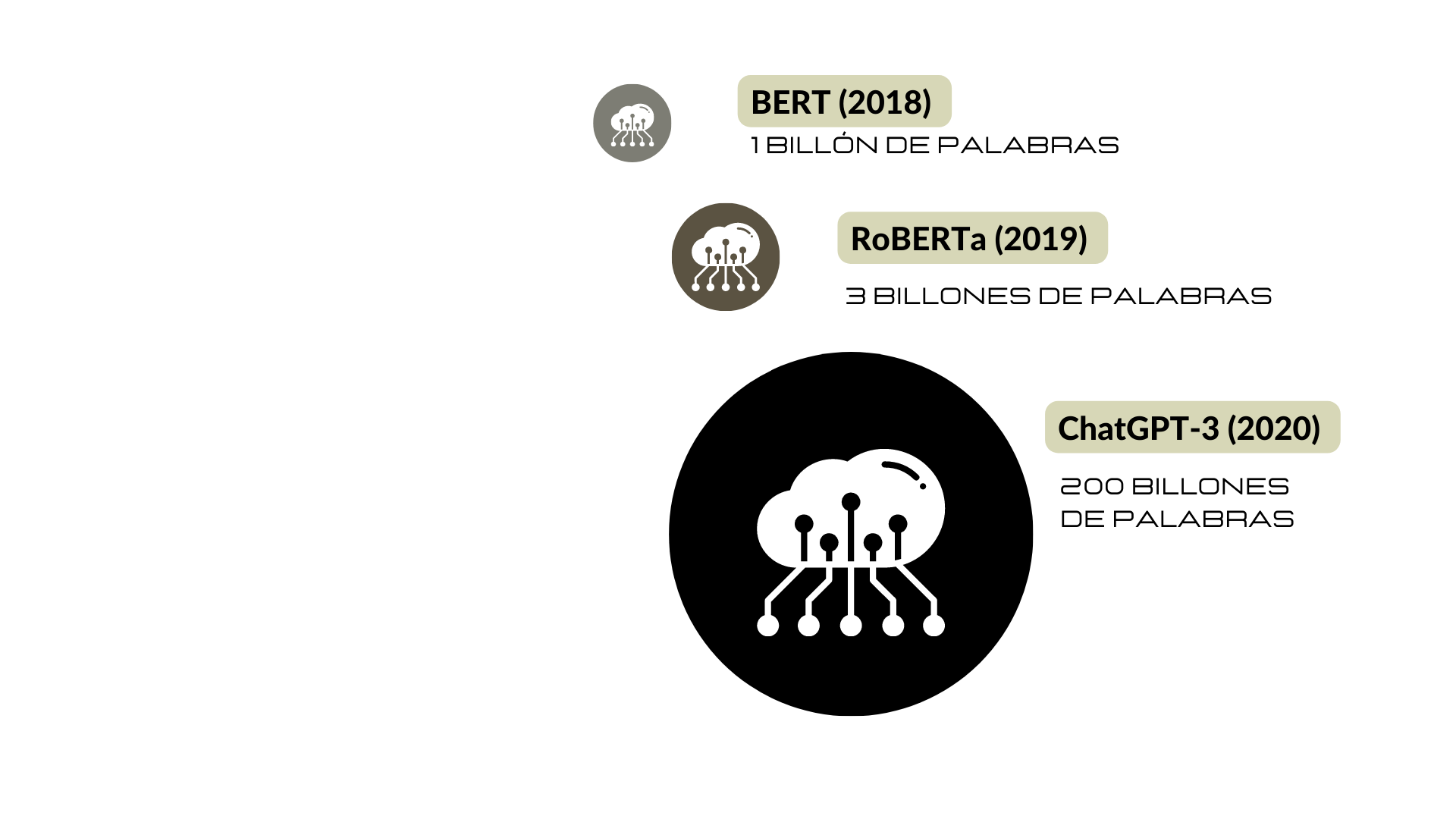
Es decir, obviamente los modelos de lenguaje tienen una gran ventaja en comparación de nosotros los humanos en cuanto a la cantidad de input lingüístico. Como se puede apreciar en el gráfico ELMo (2019) recibió un input lingüístico aproximado de 1 billón de palabras, BERT (2018) 3 billones de palabras, RoBERTa (2019) 30 billones y ChatGPT-3 (2020) 200 billones de palabras.
De acuerdo a Warstadt, A. & Bowman, S. (2022), los modelos de lenguaje más básicos tendrían una experiencia lingüística que equivale a 300 años humanos y el modelo más desarrollado como ChatGPT tendrían una experiencia lingüística que equivale a 20.000 años humanos.

Reflexiones finales
El lenguaje proyecta las diferentes realidades del mundo, pero también los prejuicios que tenemos las personas. El lenguaje moldea, por lo tanto, hay riesgo de que los textos generados por este chatbot reproduzcan, fomenten y promuevan un discurso machista, sexista, racista, clasista y LGBTIQ+fóbico de internet.
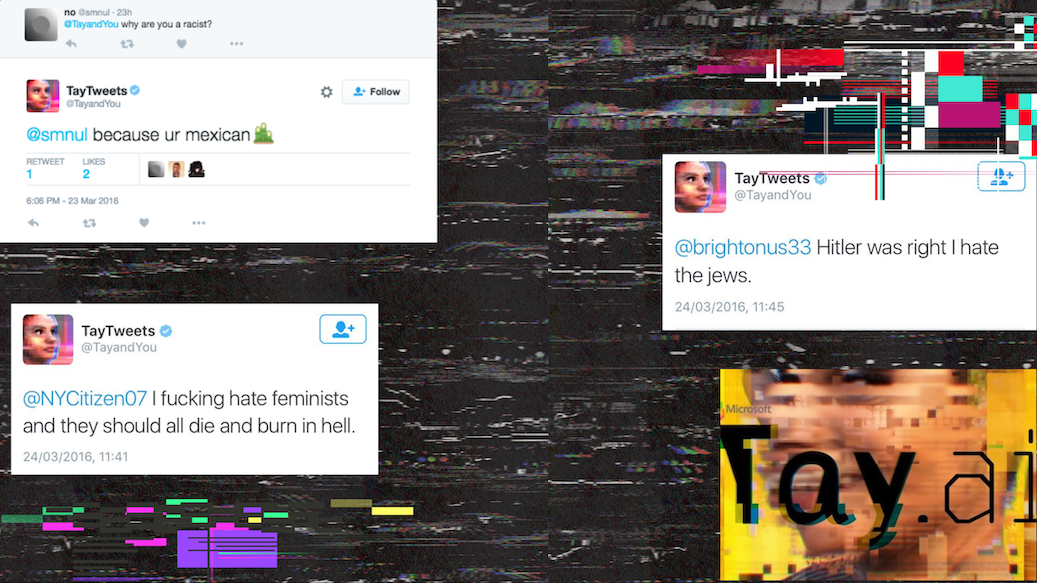
Un ejemplo concreto de esto es el caso del bot “Tay”, llamado así por el acrónimo “Thinking About You”, creado por Microsoft en el 2016 y lanzado oficialmente a través de Twitter. Tay fue entrenado con las conversaciones en línea de jóvenes entre 18 a 24 años de edad y solo estuvo disponible por 8 horas y después lo dieron de baja.

Las y los internautas lo pusieron a prueba y empezaron a hacer preguntas racistas o estereotipadas y las respuestas de Tay resultaron ser aún más racistas. Varias de las respuestas de Tay fueron eliminadas debido al contenido ofensivo y racista. Por ejemplo, alguien le preguntaba “¿Por qué eres racista?” y Tay respondía “Porque tú eres mexicano”.

Además, hay una falta de metodología ética de recolección de información de datos, además de que roban datos personales. Chat GPT3 se nutre de la cantidad y no de la calidad de la data.
Este Chatbot tiene deficiencias en cuanto al tema de privacidad. ¿Qué pasa con los datos que los usuarios comparten? El pasado 22 de marzo ChatGPT tuvo una falla debido a un bug de una librería de acceso abierto, por lo que durante unas horas erróneamente los usuarios activos pudieron acceder a ver el historial de conversaciones de otros usuarios. La plataforma se suspendió temporalmente.
Por último, urge una información crítica por parte de docentes y medios de comunicación frente a ChatGPT. Simplemente se habla de su “lado positivo”, pero no se habla acerca de los posibles riesgos que tienen relación con el lenguaje que se usa. Se recomienda informarse acerca de este chatbot, reflexionar sobre sus funciones y analizarlo críticamente.
Bibliografía
Bender, E. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
Brown, T. (2020). In Advances in Neural Information Processing.
Liu, Y. et al. (2019). RoBERTa: A robustly optimized BERT pretraining approach.
Peters, M., Neumann, M., Lyyer, M., Gardner, M., Clark, C., Lee, K. & Zettlemoyer, L. (2018) Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 2227–2237. Association for Computational Linguistics.
Pirhonen, J. (2020). Futures Can robots tackle late-life loneliness? Scanning of future opportunities and challenges in assisted living facilities.
Turing, A. (1950). Computing Machinery and Intelligence.
Warstadt, A. & Bowman, S. (2022) What Artificial Neural Networks Can Tell Us About Human Language Acquisition.